Der Data Mining Prozess lässt sich in folgende Phasen untergliedern: Aufgabendefinition, Auswahl der relevanten Datenbestände (Selection), Datenaufbereitung (Preprocessing, Transformation), Auswahl von Data Mining-Methoden, Anwendung der Data Mining-Methoden, Interpretation und Evaluation der Data Mining-Ergebnisse und Anwendung der Data Mining Ergebnisse (vgl. Hippner, Merzenich und Wilde, 2002, S. 10). Die einzelnen Phasen stehen in Interaktion mit dem Benutzer und laufen mit zahlreichen Rückkopplungen ab (vgl. Darst.).
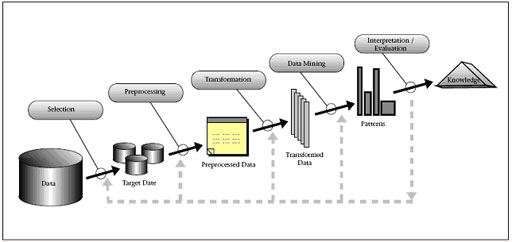
Darstellung: Data Mining / KDD Prozess; Quelle: Fayyad et. al, 1996, S. 41
Im Gegensatz zur Vision des Data Mining, neues, gültiges und handlungsrelevantes Wissen ohne konkrete Fragestellung zu entdecken, erfordert die Praxis des Data Mining eine präzise Beschreibung der betriebswirtschaftlichen Problemstellung. Daraus werden die dazu erforderlichen Datenanalyseaufgaben abgeleitet und die potentiell relevanten Daten katalogisiert und qualitativ bewertet (vgl. Hippner, Merzenich und Wilde, 2002, S. 12). Der Erste Schritt ist also die Auswahl der Daten. Dabei werden aus einem vorhandenen Datenbestand relevante Objekte (Datensätze) und Merkmale (Datenfelder) ausgewählt. Bei sehr großen Datenbeständen wird oft mit einer Stichprobe gearbeitet und die Ergebnisse durch eine zweite Stichprobe evaluiert. Die zeitaufwendigste Phase im Data Mining Prozess ist die Datenaufbereitung und Transformation (vgl. Hippner, Merzenich und Wilde, 2002, S. 19). Selbst wenn die Daten in einwandfreiem Zustand aus einem Data Warehouse gewonnen werden, erfordern die Art der Problemstellung und die methodischen Anforderungen verschiedener Data Mining-Methoden eine spezielle Aufbereitung (vgl. Hippner, Merzenich und Wilde, 2002, S. 19). Bei diesen Operationen gehen meist Daten verloren, sodass sie mit großer Sorgfalt durchzuführen sind (vgl. Alpar, Niederreichholz, 2000, S. 6-8).
Nachfolgende Darstellung zeigt die Schritte im Datenaufbereitungs-Prozess

Darstellung: Vorverarbeitung im Data Mining Prozess, Quelle: eigene Darstellung in Anlehnung an Hippner, Merzenich und Wilde, 2002, S. 19-31
Vorraussetzung für die Anwendung von Data Mining im weiteren Sinn sind die sorgfältige Auswahl, Vorverarbeitung und Transformation der Daten (vgl. Alpar, Niederreichholz, 2000, S. 6ff).
Im engeren Sinn, müssen die Daten in das Standardformat des Data Mining übertragen werden, um die Methoden Anwendbar zu machen. Das Standardformat ist eine Datentabelle (Spreadsheet), deren Zeilen die Datensätze und deren Spalten die Merkmale dieser Datensätze repräsentieren (vgl. Hippner, Merzenich und Wilde, 2002, S. 19).
Weiter zum Maschinellen Lernen und den Verfahren Klassifikation und Clusterbildung