Die Methoden des Data Mining können nach verschiedenen Kriterien klassifiziert werden. Der folgende Abschnitt basiert im Wesentlichen auf Alpar und Niederreichholz (2000, S. 9ff), die zwei Ebenen unterschieden: Aufgaben und Methoden.
Die Aufgaben des Data Mining sind Klassifikation, Segmentierung, Prognose, Abhängigkeitsanalyse und Abweichungsanalyse.
Die folgende Abbildung ordnet die Methoden den einzelnen Aufgaben zu.
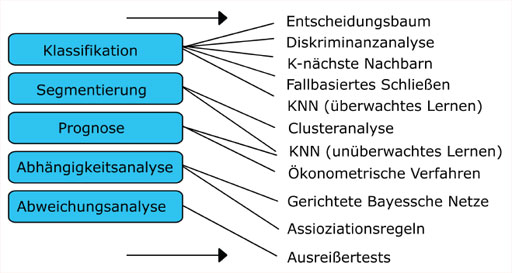
Darstellung: Zuordnung der Data Mining Methoden zu Aufgaben, Quelle: eigene Darstellung in Anlehnung an Alpar und Niederreichholz, 2000, S. 13
Bei der Klassifikation werden Klassen bzw. Kategorien definiert, denen einzelne Objekte zugeordnet werden. Dies geschieht aufgrund von Vergleichen zwischen Klasseneigenschaften und Objektmerkmalen. Der Klassifikator ist jene Funktion, die die Objekte den jeweiligen Klassen zuordnet.
Bei der Segmentierung werden die Objekte in Gruppen zusammengefasst, die nicht vorher festgelegt werden. Objekte mit gemeinsamen Eigenschaften bzw. Merkmalen werden automatisch zu Gruppen zusammengefasst.
Die Vorhersage unbekannter Merkmalswerte auf Basis anderer Merkmale oder auf Basis von Werten des gleichen Merkmals aus früheren Perioden wird als Prognose bezeichnet. Dabei kann auch Klassifikation für Prognose verwendet werden, wenn z.B. ein Bankkunde als kreditwürdig eingestuft werden soll.
Ziel der Abhängigkeitsanalyse ist das finden von Beziehungen zwischen verschiedenen Objekten oder zwischen Merkmalen eines Objektes. Dies kann sich auf einen bestimmten Zeitpunkt oder verschiedene Zeitpunkte beziehen. Z.B. könnte bei einer Warenkorbanalyse ein Zusammenhang zwischen verschiedenen Produkten festgestellt werden: Babywindeln und Bier, Diätjoghurt und Knäckebrot etc.; bei der Analyse von Kreditkartentransaktionen könnte festgestellt werden, dass 2-3 Monate nach dem Kauf einer Digitalkamera häufig ein Fotodrucker gekauft wird.
Bei der Abweichungsanalyse sollen Objekte identifiziert werden, die den Regelmäßigkeiten der anderen Objekte nicht folgen. Ziel ist das Ausmachen der Ursachen für diese Abweichungen.
Die einzelnen Aufgaben lassen sich nicht immer voneinander trennen und fallen oft gemeinsam an (vgl. Alpar und Niederreichholz, 2000, S. 9-13). So kann z.B. eine Abhängigkeitsanalyse in bestimmte Klassen bzw. Segmente durchgeführt werden.
Data Mining verwendet ein breites Spektrum an Methoden die von der Regressionsanalyse bis zu komplexen Anwendungen von neuronalen Netzten reichen. Im Folgenden werden einige davon beschrieben und den einzelnen Aufgaben zugeordnet.
Dies sind Entscheidungsbäume, Diskriminanzanalysen, K-nächste Nachbarn, Clusteranalyse, Künstliche Neuronale Netze (KNN), Fallbasiertes Schließen, Ökonometrische Verfahren, Gerichtete Bayessche Netze, Assoziationsregeln, Ausreißertests. Im Folgenden werden diese kurz beschrieben und den einzelnen Aufgaben zugeordnet.
Entscheidungsbäume wurden am weitesten im Bereich des Maschinellen Lernens entwickelt. Dabei werden Objekte, deren Klassenzuordnung bekannt ist, sukzessive mit Hilfe einzelner Merkmale in Gruppen aufgeteilt, die in sich homogen, aber voneinander möglichst unterschiedlich sind. Am Ende entsteht der Entscheidungsbaum, aus dem Regeln abgeleitet werden können, die auf nicht zugeordnete Objekte angewendet werden. Entscheidungsbäume werden, wie traditionelle statistische Verfahren (Diskriminanzanalyse, k-nächste-Nachbarn oder logistische Regression) hauptsächlich zur Klassifikation eingesetzt (vgl. Alpar und Niederreichholz, 2000, S. 11).
Clusteranalysen unterteilen Objekte in möglichst homogene Gruppen. Die Objekte einer Klasse sollen dabei hinsichtlich ihrer Merkmalsausprägungen möglichst ähnlich, Objekte aus verschiedenen Klassen möglichst unterschiedlich sein (vgl. Hippner, Merzenich und Wilde, 2002, S. 32). Die Bedeutung der entstehenden Gruppen bzw. Cluster muss am Ende des Prozesses bestimmt werden. Dazu werden Objekte verwendet, die das Clusterzentrum bilden, oder sich in seiner Näher befinden.
Künstliche neuronale Netze (KNN) verwenden Erkenntnisse der Hirnforschung, um Lernvorgänge zu realisieren. Sog. Neuronen werden in Schichten angeordnet, in denen alle Neuronen einer Schicht mit allen Neuronen der Nachbarschichten verbunden sind. Die Input-Schicht nimmt als erste Schicht die zu verarbeitenden Daten auf, die letzte Schicht (Outputschicht) liefert das Ergebnis. Die Neuronen verarbeiten die eingehenden Daten derart, dass diese aufsummiert werden und nur bei Überschreiten eines Schwellenwertes einen Wert an die nachfolgenden Neuronen weitergeben (vgl. Alpar und Niederreichholz, 2000, S. 11-12). Beim überwachten Lernen werden dem KNN Beispiele präsentiert, deren Ergebnisse bekannt sind (z.B. die Einteilung von Dokumenten in vordefinierte Klassen) bis es die gewünschten Ergebnisse erzielt. Es gibt auch selbstorganisierende KNN, die unüberwachtes Lernen ermöglichen und sich besonders für Aufgaben der Segmentierung oder der Prognose eignen.
Assoziationsregeln untersuchen gemeinsame Vorkommen von Merkmalswerten in Datensätzen, um ihre gegenseitige Abhängigkeit zu untersuchen. Daraus werden Regeln abgeleitet, die durch die Stärke der Abhängigkeit und die Häufigkeit ihres Vorkommens charakterisiert werden (vgl. Alpar und Niederreichholz, 2000, S. 12).
Case-Based Reasoning (CBR) bedeutet fallbasiertes Schließen. Dabei handelt es sich um eine Methode, mit der man Lösungen zu neuen Problemen aufgrund von Lösungen zu bereits gelösten und gespeicherten Problemen ermittelt. Basierend auf der Ähnlichkeit der Merkmale des gespeicherten Problems und des neuen Problems wird eine Lösung ausgewählt. Bei der Ermittlung von Ähnlichkeiten werden sprachliche und strukturelle Beziehungen zwischen den merkmalswerten betrachtet. CBR eignet sich deshalb zur Klassifikation.
Die "Explorationslast einer Wissensexploration" kann bzw. liegt häufig auf der Seite des Anwenders und Betrachters; Lesen sie weiter, wie Visualisierungstechniken eine Exploration ermöglichen und den Grundstein für Hypothesen und Wissensorganisation legen.